
On Device LLM 本地AI工作台



依托MLX框架实现设备端模型运行,无服务器依赖,功能覆盖代码辅助、语音对话、实时字幕,适配多场景。
依托MLX框架实现设备端模型运行,无服务器依赖,功能覆盖代码辅助、语音对话、实时字幕,适配多场景。
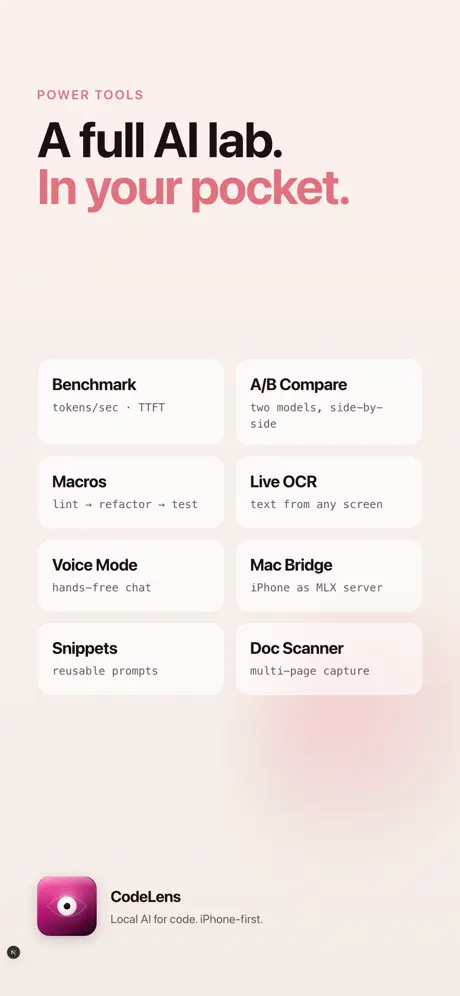
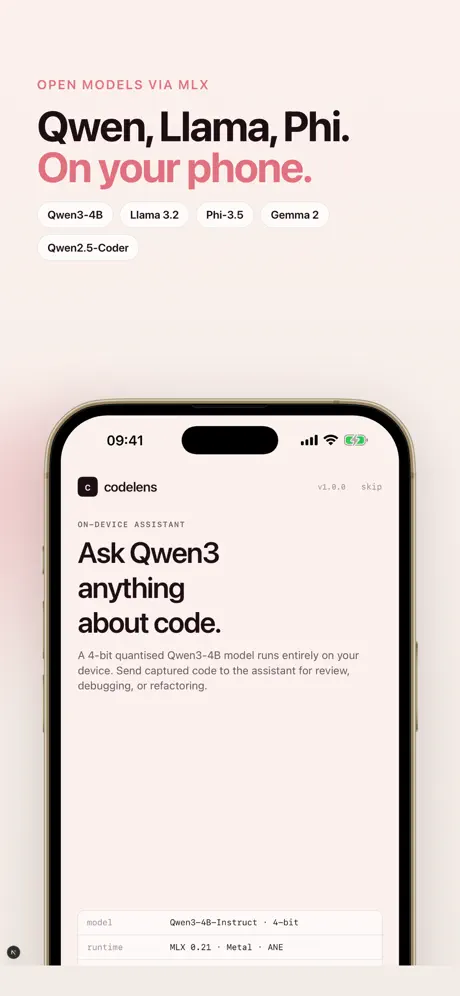
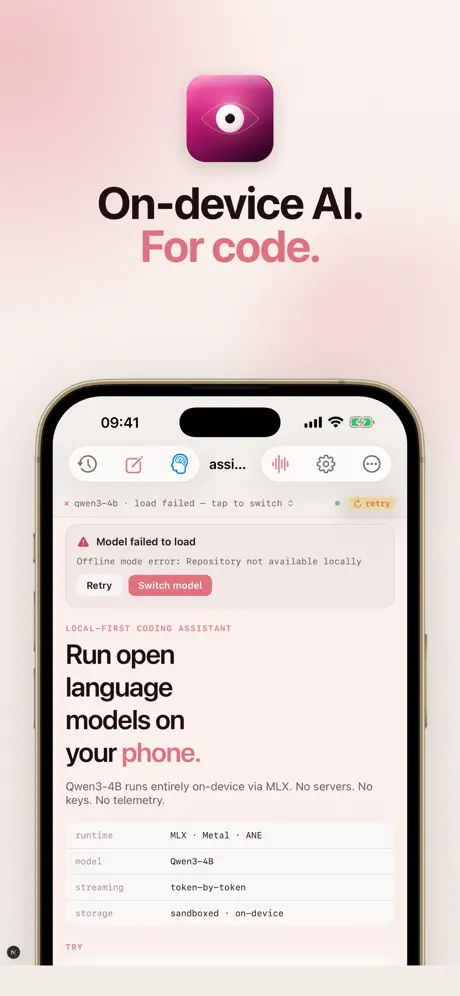

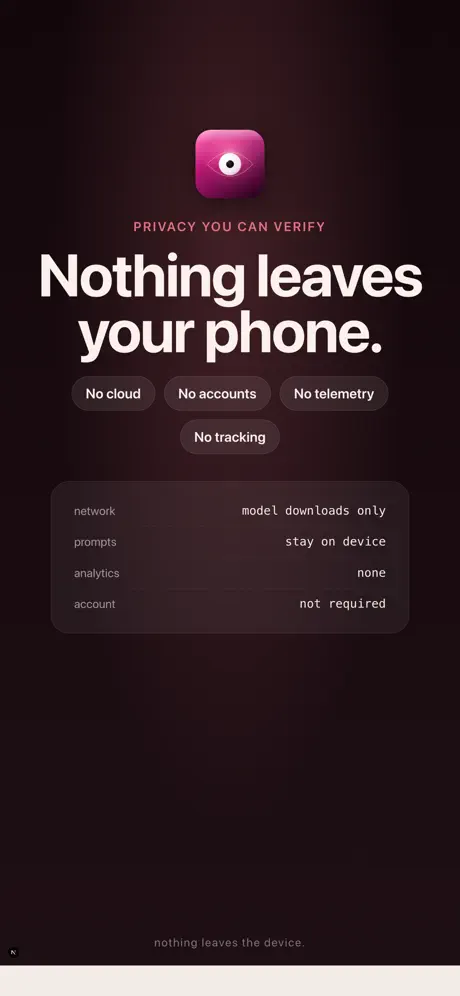
本地优先的AI工作台,适用于您的iPhone。开源的语言和视觉模型通过Apple的MLX框架完全在设备上运行——无需服务器、API密钥、遥测数据或账户。 实时摄像头字幕 将摄像头指向任何物体。SmolVLM每几秒钟描述一次场景,并将字幕直接流式传输到取景器中。将刷新间隔从500毫秒调整至30秒。点击刷新图标,在周期之间进行按需字幕。 语音对话 与设备上的LLM进行免提聊天。行业标准的语音活动检测忽略电视谈话和背景噪音;通过它正在收听的同一音频会话进行回应——不会出现截断的第一个词或延迟回复。 代码助手 从Qwen 2.5 Coder、Llama 3.2、Phi-3.5、Gemma 2、Qwen3以及HuggingFace上的数十个MLX转换模型中进行选择。应用程序自动选择适合您设备RAM(旧款iPhone为15亿,Pro Max高达70亿)的模型。流式传输逐个令牌的输出,代码块语法高亮,对话导出为Markdown。 实用工具 • 文档扫描仪——通过原生四角文档摄像头捕获多页代码 • 实时OCR——屏幕上的文本、签名或白板实时识别 • A/B对比——并排运行两个模型,观察速度/质量权衡 • 基准测试——测量每秒令牌数、首次令牌时间、峰值内存、热影响 • 宏——将提示链接在一起(lint → refactor → test) • 代码片段——保存可重用的提示模板 • 人物记忆——每个角色记住不同的事实 • Mac Bridge——配对您的Mac,使用iPhone作为MLX推理服务器 您可以验证的隐私 • 每个模型都在设备上运行——您的提示从未离开手机 • 每次出站请求时,网络活动指示器都会出现(仅限模型下载) • 会话以静态加密存储 • 设置中的一键“清除设备上所有数据” • 无需分析SDK,无需注册,无需账户 为您的设备优化 • 首次启动时自动选择设备层级的聊天模型和摄像头VLM • Pro Max上为SmolVLM 2.2B(bf16);入门级iPhone上为SmolVLM 4位 • 当模型镜像无法访问时,自动回退链 • 热感知——仅在.critical时限制响应长度(与设备上的同行应用程序匹配) • 应用程序后台时取消正在进行的Metal工作,以免iOS将其终止 要求 • iOS 18.0或更高版本 • 推荐:iPhone 12或更新版本 • 初始模型下载建议使用Wi-Fi(约1.5 GB最小) 开源模型。开放标准。您的数据不在其他人的服务器上。




